Large enterprises running Kubernetes fleets need control, safety, and auditability during cluster updates. Prior to run gating, Fleet Manager update runs executed automatically once started.
That worked for small rollouts but broke for enterprise scenarios where updates span hundreds of clusters and failures have a high blast radius.
Customers needed to pause execution, require explicit human approval, and resume only when the right operator signed off — without losing visibility into which stage, group, or cluster was affected.
I treated this as a systems-design problem, not a single-screen UI exercise. Mapped the end-to-end lifecycle and identified two distinct moments: Create time (defining strategy and gates) and Run time (active execution encountering a gate).
Rather than introducing new abstractions, I anchored the experience to concepts users already understood — Stages, Groups, and Run state.
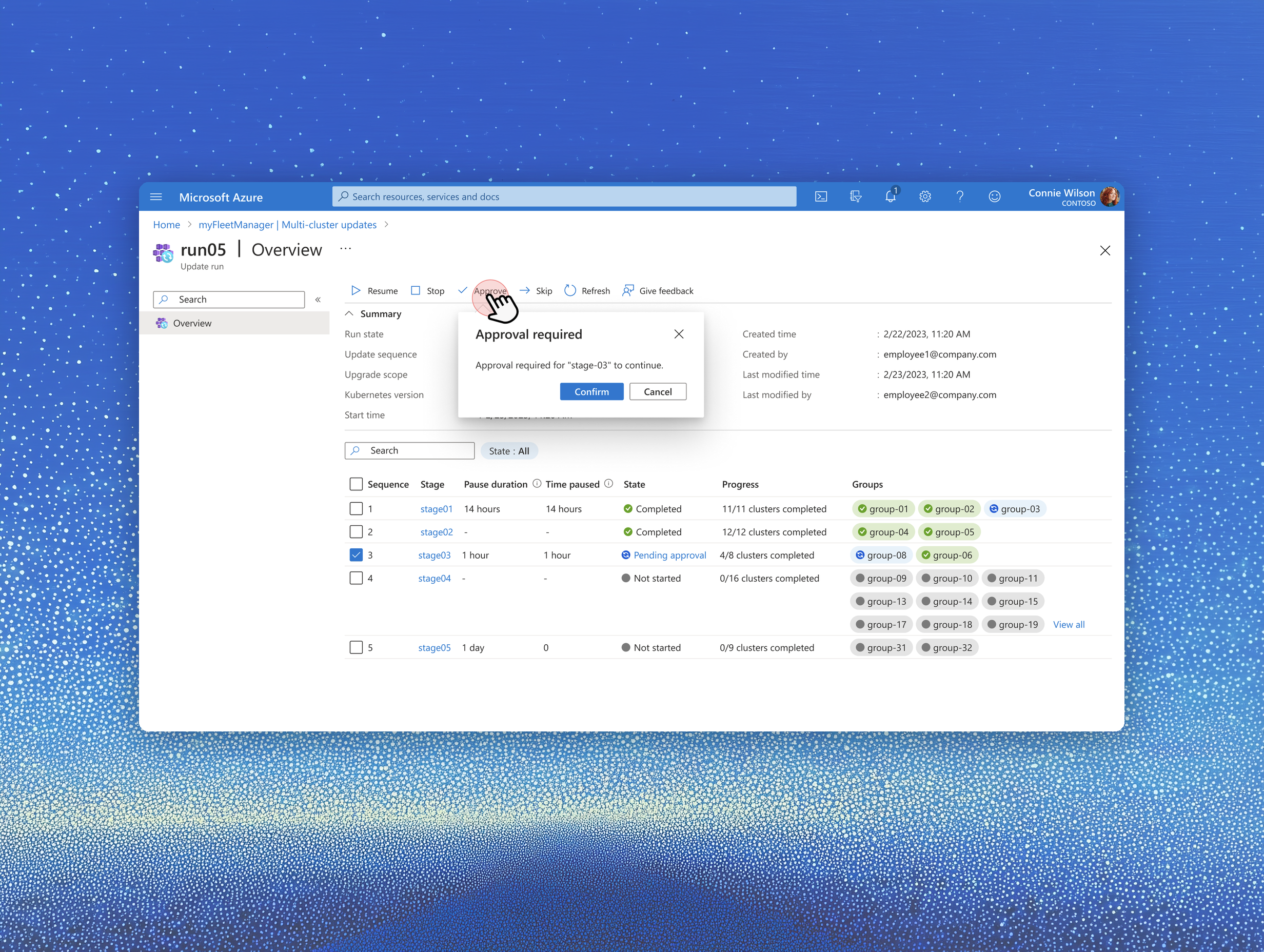
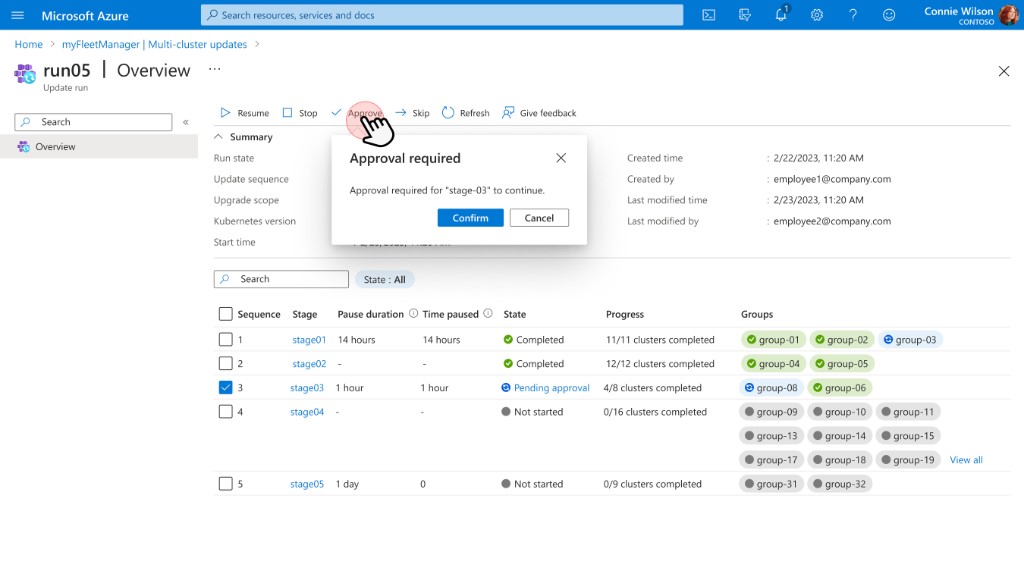
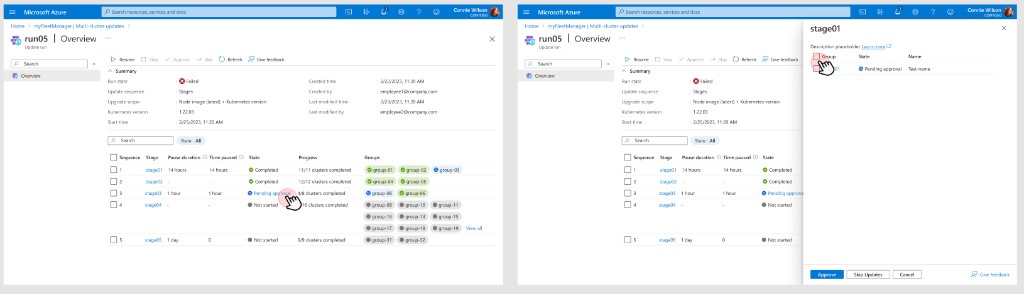
Approvals became a first-class run state: the UI reflects that the system is intentionally paused, not broken or stalled.
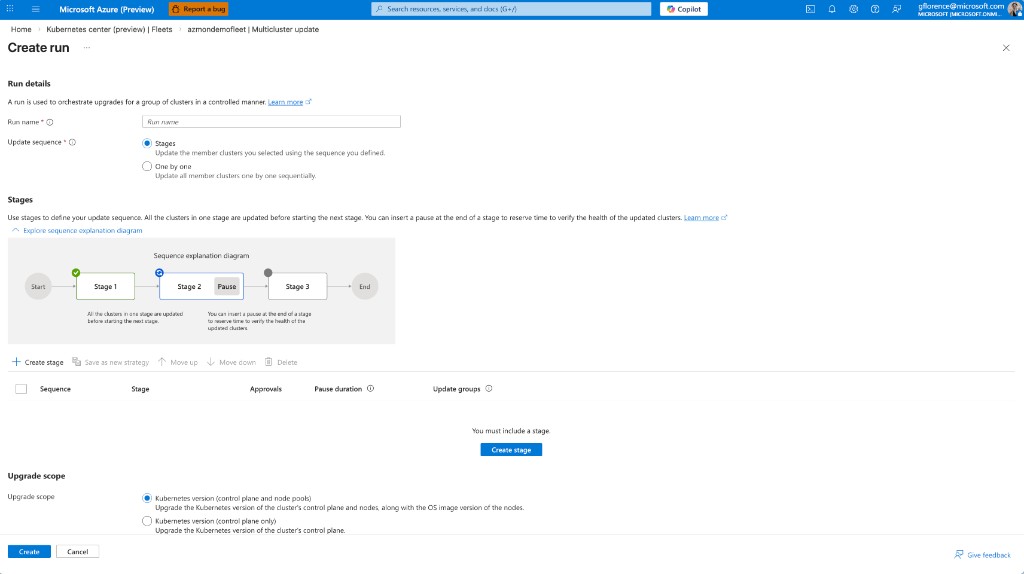
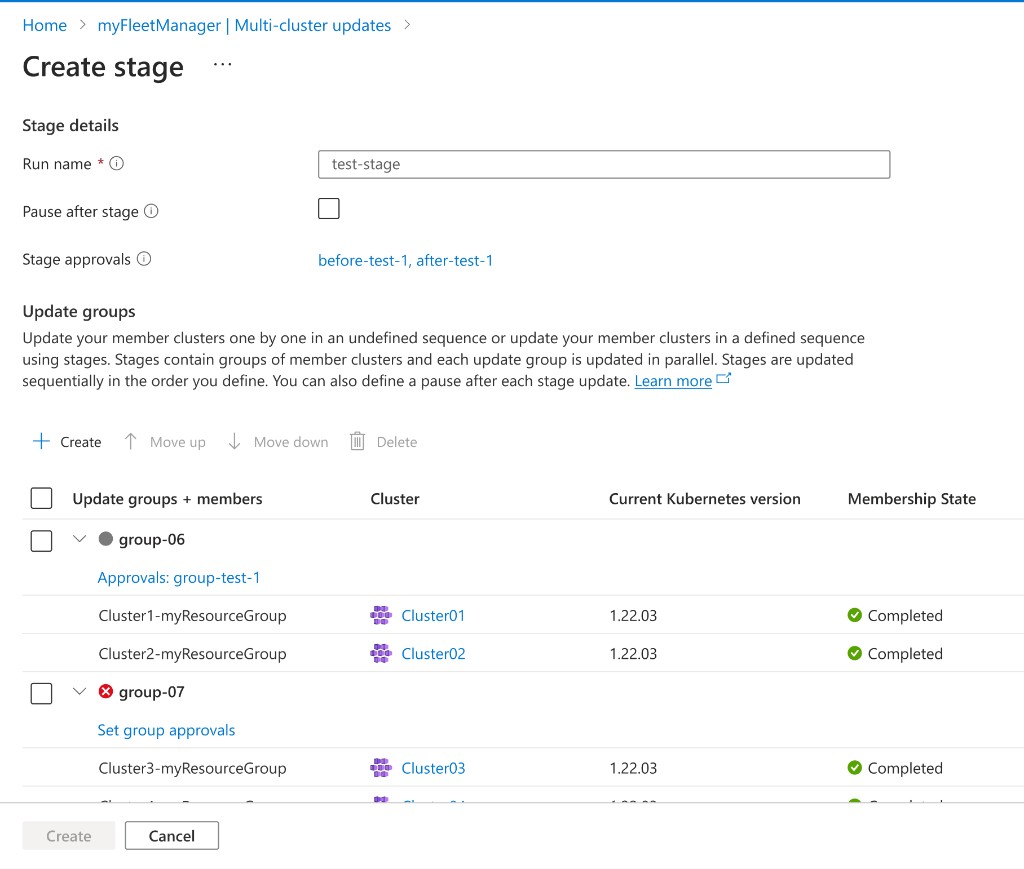
Shipped in two connected parts. Create: operators can encode operational policy before any update begins by adding approval gates while authoring an update strategy.
Manage: when a run reaches a gate, its state becomes "Awaiting approval" — operators can approve and resume, skip the gated scope, or stop the run entirely using standard Azure action-bar controls. All actions are auditable.
Unlocked safe human-in-the-loop updates at fleet scale, reducing operational risk for high-blast-radius changes and unblocking enterprise customers with formal compliance requirements.
Established a reusable pattern for future control-plane features in Azure.